
En dos líneas: En post anteriores mencionaba una de las "v" más destacadas del Big Data, la variedad de datos, dicha variedad responde tanto a su origen como a su tipología.
A pesar de que pueda parece que nos enfrentamos al típico caso de tipologías complicadas y con múltiples sub-divisiones, no hay nada de eso, de hecho se puede decir que básicamente hay dos tipos de datos en el Big Data:
- Datos Estructurados
- Datos No estructurados
Quizás haya lugar para mencionar brevemente una tipología intermedia, la de los datos semiestructurados (formatos como EDI, SWIFT, XML), que como en otros casos donde nos encontramos con el prefijo "semi" no son objeto de consenso en su definición.
Pero vayamos al grano:
Datos Estructurados
La definición es bien sencilla, son datos estructurados todos aquellos que tienen definida su longitud y su formato.
Y suelen ser:
- Números
- Fechas
- Combinaciones de números y palabras, conocidas como "strings": por ejemplo el nombre de un cliente, su número de DNI, una dirección postal, un mail, etc...

Los datos estructurados son aproximadamente el 20% de los datos que encontramos en los sistemas de una empresa.
¿Y dónde los encontramos?, pues básicamente tienen su origen en los transaccionales (a saber: ERP y CRM) y suelen estar ubicados en data warehouses y datamarts. Vamos, que son los datos de finanzas, ventas, almacenes, etc...
Los consultamos generalmente a través del lenguaje SQL, en inglés Structured Query Language.
De hecho, la mayoría de soluciones de Business Intelligence y Business Analytics trabajan con este tipo de datos casi en exclusiva.
Y a pesar de lo que pueda parecer, los datos estructurados tienen un gran papel en el Big Data, lo entenderemos mejor si vemos cuál es su origen:
- Datos generados por máquinas y computadoras.
- Datos generados por personas, o sea, datos picados por personas en un ordenador.
Dentro de los datos estructurados generados por máquinas destacamos:
- Datos procedentes de sensores: hay múltiples ejemplos como los procedentes de un GPS como el que podríamos encontrar en nuestro smartphone, las etiquetas RFID, tacómetros, contadores, equipos médicos, etc....
- Web Log Data: servidores, redes, aplicaciones, etc.. generan grandes cantidades de datos estructurados.
- Datos procedentes de puntos de venta: basta con pensar en un hipermercado con una cajera pasando códigos de barras por un lector.
- Datos financieros: muchas operaciones bancarias y bursátiles son de datos estructurados generados automáticamente.
Los datos estructurados generados por personas también son variados y pasan desde los registros de una contabilidad en un ERP pasando por el hecho de cumplimentar un formulario en una web o incluso nuestros movimientos en uno de esos juegos on-line que ahora nos encontramos en Facebook.
No hace falta pensar mucho para ver como estos datos están asociados a otras "v" como volumen y velocidad.
Los datos estructurados son la piedra angular de las bases de datos relacionales sobre las que operan la casi totalidad de los sistemas informáticos en empresas y administración y hay que tener muy claro que el Big Data además utiliza otros tipos de bases de datos no relacionales, es el mundo No-SQL.
En los modelos relacionales la información está almacenada en tablas y las bases de datos están dotadas de un esquema, esto es, de una representación de la estructura de dicha base de datos. Así el esquema define las tablas, los campos en las tablas y las relaciones entre ambos.
Un ejemplo sería el que proponemos a continuación, donde una tabla almacena la información de productos y la otra información sociodemográfica de los clientes que compran dichos productos:
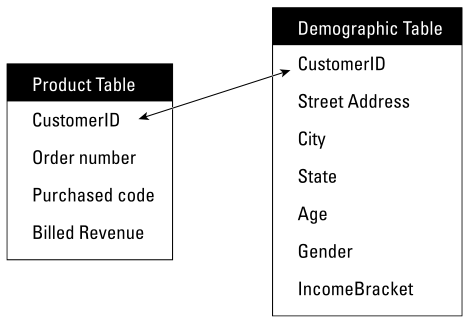
Y la vinculación entre las tablas la da un campo clave, en este caso, el cliente (Customer ID) y cualquier consulta que se hiciese a esa base de datos sería en lenguaje SQL
Datos No Estructurados
Su definición también es sencilla, son opuestos a los datos estructurados, en el sentido de que, al contrario que aquellos, carecen de un formato específico.
Si antes decíamos que el 20% de los datos están estructurados, ahora hemos de reconocer que el 80% restante no lo está, y sólo en los últimos años disponemos de la tecnología que nos permite aprovechar dichos datos y, lo que es más importante aún, hacerlo a costes razonables.
Al igual que los datos estructurados, los no estructurados son generados bien por máquinas:
- Imagenes de satélites.
- Datos científicos: gráficos sísmicos, atmosféricos, etc..
- Fotografía y vídeo: por ejemplo cámaras de vigilancia.
- Datos de sónar y radar.

Bien por personas:
- Textos incluidos dentro de los sistemas de información internos de las organizaciones: basta con pensar en documentos, presentaciones, correos electrónicos, etc...
- Datos provenientes de redes sociales: a saber, Twitter, Facebook, LinkedIn, Flickr, Instragram, Tuenti, etc....
- Datos provenientes de nuestros dispositivos móviles: pensemos en los mensajes que enviamos con nuestros teléfonos móviles.
- Contenido de sitios web: podemos ir desde vídeos de YouTube hasta este humilde blog.

Y estos ejemplos podrían continuar y continuar...
Hay que tener muy claro que en el Big Data hay sitio tanto para los datos estructurados como para los no estructurados, para el No-SQL y para el SQL (vemos gran actividad en ese sentido), generados por personas o por máquinas.
Si pensamos en la analítica de textos que se aplica a lo que escriben los clientes de una determinada marca de coches (lo que sería un análisis de sentimiento) o de un operador de telefonía móvil, lo que se hace partir del análisis de textos (datos no estructurados) para obtener datos estructurados que nos expliquen qué está sucediendo.
El Mes del Big Data en Outsourceando
1) Definición del Big Data
2) Las 3 "V" del Big Data
3) ¿Cuál es estado actual del Big Data?
4) ¿Por qué el Big Data ahora?
5) Tipos de datos que encontramos en el Big Data
No hay comentarios:
Publicar un comentario